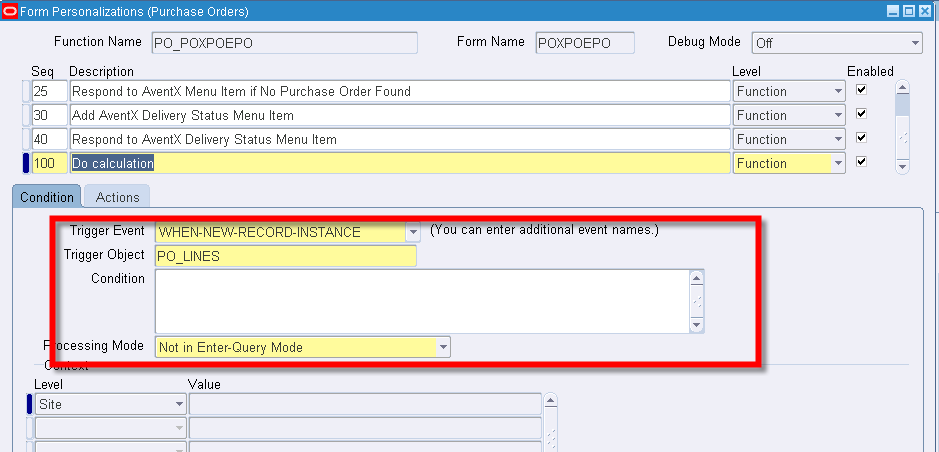
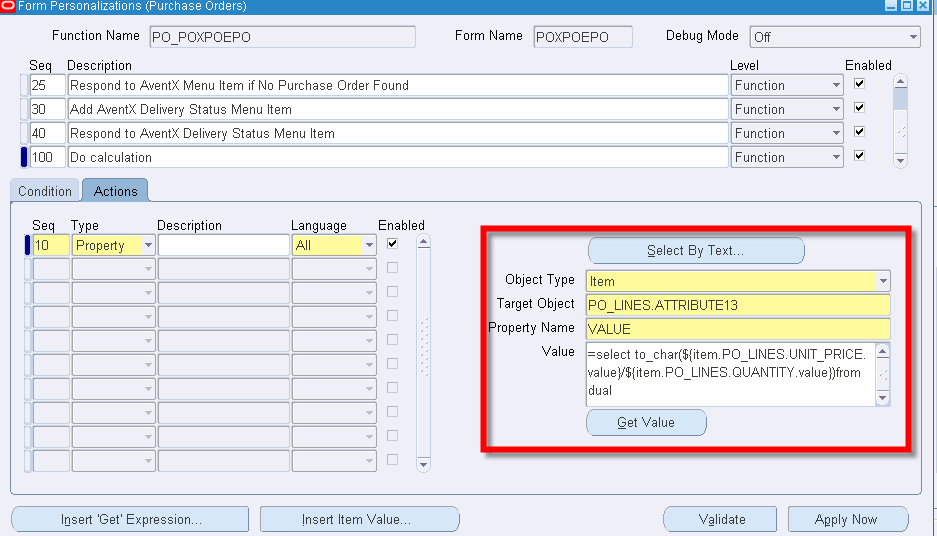
Related articles.
Introduction
Oracle 10g introduced support support for regular expressions in SQL and PL/SQL with the following functions.
- REGEXP_INSTR - Similar to INSTR except it uses a regular expression rather than a literal as the search string.
- REGEXP_LIKE - Similar to LIKE except it uses a regular expression as the search string. REGEXP_LIKE is really an operator, not a function.
- REGEXP_REPLACE - Similar to REPLACE except it uses a regular expression as the search string.
- REGEXP_SUBSTR - Returns the string matching the regular expression. Not really similar to SUBSTR.
Oracle 11g introduced two new features related to regular expressions.
- REGEXP_COUNT - Returns the number of occurrences of the regular expression in the string.
- Sub-expression support was added to all regular expression
functions by adding a parameter to each function to specify the
sub-expression in the pattern match.
Learning to write regular expressions takes a little time. If you
don't do it regularly, it can be a voyage of discovery each time. The
general rules for writing regular expressions are available
here. You can read the Oracle Regular Expression Support
here.
Rather than trying to repeat the formal definitions, I'll present a
number of problems I've been asked to look at over the years, where a
solution using a regular expression has been appropriate.
Example 1 : REGEXP_SUBSTR
The data in a column is free text, but may include a 4 digit year.
DROP TABLE t1;
CREATE TABLE t1 (
data VARCHAR2(50)
);
INSERT INTO t1 VALUES ('FALL 2014');
INSERT INTO t1 VALUES ('2014 CODE-B');
INSERT INTO t1 VALUES ('CODE-A 2014 CODE-D');
INSERT INTO t1 VALUES ('ADSHLHSALK');
INSERT INTO t1 VALUES ('FALL 2004');
COMMIT;
SELECT * FROM t1;
DATA
----------------------------------------------------------------------------------------------------
FALL 2014
2014 CODE-B
CODE-A 2014 CODE-D
ADSHLHSALK
FALL 2004
5 rows selected.
SQL>
If we needed to return rows containing a specific year we could use the
LIKE operator (
WHERE data LIKE '%2014%'), but how do we return rows using a comparison (<, <=, >, >=, <>)?
One way to approach this is to pull out the 4 figure year and convert
it to a number, so we don't accidentally do an ASCII comparison. That's
pretty easy using regular expressions.
We can identify digits using the "\d" or "[0-9]" operators. We want a
group of four of them, which is represented by the "{4}" operator. So
our regular expression will be "\d{4}" or "[0-9]{4}". The
REGEXP_SUBSTR
function returns the string matching the regular expression, so that
can be used to extract the text of interest. We then just need to
convert it to a number and perform our comparison.
SELECT *
FROM t1
WHERE TO_NUMBER(REGEXP_SUBSTR(data, '\d{4}')) >= 2014;
DATA
----------------------------------------------------------------------------------------------------
FALL 2014
2014 CODE-B
CODE-A 2014 CODE-D
3 rows selected.
SQL>
Example 2 : REGEXP_SUBSTR
Given a source string, how do we split it up into separate columns,
based on changes of case and alpha-to-numeric, such that this.
ArtADB1234567e9876540
Becomes this.
Art ADB 1234567 e 9876540
The source data is set up like this.
DROP TABLE t1;
CREATE TABLE t1 (
data VARCHAR2(50)
);
INSERT INTO t1 VALUES ('ArtADB1234567e9876540');
COMMIT;
The first part of the string is an initcap word, so it starts with a
capital letter between "A" and "Z". We identify a single character using
the "[]" operator, and ranges are represented using "-", like "A-Z",
"a-z" or "0-9". So if we are looking for a single character that is a
capital letter, we need to look for "[A-Z]". That needs to be followed
by lower case letters, which we now know is "[a-z]", but we need 1 or
more of them, which is signified by the "+" operator. So to find an
initcap word, we need to search for "[A-Z][a-z]+". Since we want the
first occurrence of this, we can use the following.
REGEXP_SUBSTR(data, '[A-Z][a-z]+', 1, 1)
The second part of the string is a group of 1 or more uppercase
letters. We know we need to use the "[A-Z]+" pattern, but we need to
make sure we don't get the first capital letter, so we look for the
second occurrence.
REGEXP_SUBSTR(data, '[A-Z]+', 1, 2)
The next part is the first occurrence of a group of numbers.
REGEXP_SUBSTR(data, '[0-9]+', 1, 1)
The next part is a group of lower case letters. We don't to pick up
those from the initcap word, so we must look for the second occurrence
of lower case letters.
REGEXP_SUBSTR(data, '[a-z]+', 1, 2)
Finally, we have a group of numbers, which is the second occurrence of this pattern.
REGEXP_SUBSTR(data, '[0-9]+', 1, 2)
Putting that all together, we have the following query, which splits the data into separate columns.
COLUMN col1 FORMAT A15
COLUMN col2 FORMAT A15
COLUMN col3 FORMAT A15
COLUMN col4 FORMAT A15
COLUMN col5 FORMAT A15
SELECT REGEXP_SUBSTR(data, '[A-Z][a-z]+', 1, 1) col1,
REGEXP_SUBSTR(data, '[A-Z]+', 1, 2) col2,
REGEXP_SUBSTR(data, '[0-9]+', 1, 1) col3,
REGEXP_SUBSTR(data, '[a-z]+', 1, 2) col4,
REGEXP_SUBSTR(data, '[0-9]+', 1, 2) col5
FROM t1;
COL1 COL2 COL3 COL4 COL5
--------------- --------------- --------------- --------------- ---------------
Art ADB 1234567 e 9876540
1 row selected.
SQL>
Example 3 : REGEXP_SUBSTR
We need to pull out a group of characters from a "/" delimited
string, optionally enclosed by double quotes. The data looks like this.
DROP TABLE t1;
CREATE TABLE t1 (
data VARCHAR2(50)
);
INSERT INTO t1 VALUES ('978/955086/GZ120804/10-FEB-12');
INSERT INTO t1 VALUES ('97/95508/BANANA/10-FEB-12');
INSERT INTO t1 VALUES ('97/95508/"APPLE"/10-FEB-12');
COMMIT;
We are looking for 1 or more characters that are not "/", which we do
using "[^/]+". The "^" in the brackets represents NOT and "+" means 1
or more. We also want to remove optional double quotes, so we add that
as a character we don't want, giving us "[^/"]+". So if we want the data
from the third column, we need the third occurrence of this pattern.
SELECT REGEXP_SUBSTR(data, '[^/"]+', 1, 3) AS element3
FROM t1;
ELEMENT3
----------------------------------------------------------------------------------------------------
GZ120804
BANANA
APPLE
3 rows selected.
SQL>
Example 4 : REGEXP_REPLACE
We need to take an initcap string and separate the words. The data looks like this.
DROP TABLE t1;
CREATE TABLE t1 (
data VARCHAR2(50)
);
INSERT INTO t1 VALUES ('SocialSecurityNumber');
INSERT INTO t1 VALUES ('HouseNumber');
COMMIT;
We need to find each uppercase character "[A-Z]". We want to keep
that character we find, so we will make that pattern a sub-expression
"([A-Z])", allowing us to refer to it later. For each match, we want to
replace it with a space, plus the matching character. The space is
pretty obvious, but we need to use "\1" to signify the text matching the
first sub expression. So we will replace the matching pattern with a
space and itself, " \1". We don't want to replace the first letter of
the string, so we will start at the second occurrence.
SELECT REGEXP_REPLACE(data, '([A-Z])', ' \1', 2) AS hyphen_text
FROM t1;
HYPHEN_TEXT
----------------------------------------------------------------------------------------------------
Social Security Number
House Number
2 rows selected.
SQL>
Example 5 : REGEXP_INSTR
We have a specific pattern of digits (9 99:99:99) and we want to know the location of the pattern in our data.
DROP TABLE t1;
CREATE TABLE t1 (
data VARCHAR2(50)
);
INSERT INTO t1 VALUES ('1 01:01:01');
INSERT INTO t1 VALUES ('.2 02:02:02');
INSERT INTO t1 VALUES ('..3 03:03:03');
COMMIT;
We know we are looking for groups of numbers, so we can use "[0-9]"
or "\d". We know the amount of digits in each group, which we can
indicate using the "{n}" operator, so we simply describe the pattern we
are looking for.
SELECT REGEXP_INSTR(data, '[0-9] [0-9]{2}:[0-9]{2}:[0-9]{2}') AS string_loc_1,
REGEXP_INSTR(data, '\d \d{2}:\d{2}:\d{2}') AS string_loc_2
FROM t1;
STRING_LOC_1 STRING_LOC_2
------------ ------------
1 1
2 2
3 3
3 rows selected.
SQL>
Example 6 : REGEXP_LIKE and REGEXP_SUBSTR
We have strings containing parentheses. We want to return the text
within the parentheses for those rows that contain parentheses.
DROP TABLE t1;
CREATE TABLE t1 (
data VARCHAR2(50)
);
INSERT INTO t1 VALUES ('This is some text (with parentheses) in it.');
INSERT INTO t1 VALUES ('This text has no parentheses.');
INSERT INTO t1 VALUES ('This text has (parentheses too).');
COMMIT;
The basic pattern for text between parentheses is "\(.*\)". The "\"
characters are escapes for the parentheses, making them literals.
Without the escapes they would be assumed to define a sub-expression.
That pattern alone is fine to identify the rows of interest using a
REGEXP_LIKE operator, but it is not appropriate in a
REGEXP_SUBSTR,
as it would return the parentheses also. To omit the parentheses we
need to include a sub-expression inside the literal parentheses
"\((.*)\)". We can then
REGEXP_SUBSTR using the first sub expression.
COLUMN with_parentheses FORMAT A20
COLUMN without_parentheses FORMAT A20
SELECT data,
REGEXP_SUBSTR(data, '\(.*\)') AS with_parentheses,
REGEXP_SUBSTR(data, '\((.*)\)', 1, 1, 'i', 1) AS without_parentheses
FROM t1
WHERE REGEXP_LIKE(data, '\(.*\)');
DATA WITH_PARENTHESES WITHOUT_PARENTHESES
-------------------------------------------------- -------------------- --------------------
This is some text (with parentheses) in it. (with parentheses) with parentheses
This text has (parentheses too). (parentheses too) parentheses too
2 rows selected.
SQL>
Example 7 : REGEXP_COUNT
We need to know how many times a block of 4 digits appears in text. The data looks like this.
DROP TABLE t1;
CREATE TABLE t1 (
data VARCHAR2(50)
);
INSERT INTO t1 VALUES ('1234');
INSERT INTO t1 VALUES ('1234 1234');
INSERT INTO t1 VALUES ('1234 1234 1234');
COMMIT;
We can identify digits using "\d" or "[0-9]" and the "{4}" operator
signifies 4 of them, so using "\d{4}" or "[0-9]{4}" with the
REGEXP_COUNT function seems to be a valid option.
SELECT REGEXP_COUNT(data, '[0-9]{4}') AS pattern_count_1,
REGEXP_COUNT(data, '\d{4}') AS pattern_count_2
FROM t1;
PATTERN_COUNT_1 PATTERN_COUNT_2
--------------- ---------------
1 1
2 2
3 3
3 rows selected.
SQL>
Example 8 : REGEXP_LIKE
We need to identify invalid email addresses. The data looks like this.
DROP TABLE t1;
CREATE TABLE t1 (
data VARCHAR2(50)
);
INSERT INTO t1 VALUES ('me@example.com');
INSERT INTO t1 VALUES ('me@example');
INSERT INTO t1 VALUES ('@exmaple.com');
INSERT INTO t1 VALUES ('me.me@example.com');
INSERT INTO t1 VALUES ('me.me@ example.com');
INSERT INTO t1 VALUES ('me.me@example-example.com');
COMMIT;
The following test gives us email addresses that approximate to invalid email address formats.
SELECT data
FROM t1
WHERE NOT REGEXP_LIKE(data, '[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}', 'i');
DATA
--------------------------------------------------
me@example
@exmaple.com
me.me@ example.com
3 rows selected.
SQL>
=======================================================
Divide the row to multi - row
===================
REGEXP_SUBSTR (
REPLACE (REPLACE (COLUMN_NAME, '::', ' '), ':', ''),
'[0-9]+',
1,
1
)
"name123456",
REGEXP_SUBSTR (
REPLACE (REPLACE (COLUMN_NAME, '::', ','), ':', ''),
'[0-9]+',
1,
2
)
"name",
For more information see:
Hope this helps. Regards Tim...